Text Analysis Without Programming
Lynn Cherny
Visiting Knight Chair
School of Comm, U of Miami
@arnicas / lynn@cherny.com
or click right/down arrow
to go into a topic.
use the space bar to hit every slide!
Caveat: A talk at the intersection of data vis, journalism, and digital humanities
(Also: Focus here is on free or very cheap tools)
What is text data?
- Unstructured text write-ins on surveys
- PDF Documents
- Books (free or not)
- Articles (magazine, news, blog...)
- Comments on articles
- Tweets, Facebook posts
- Reviews (books, restaurants)
- Prisoners' last words on Death Row
- TV show closed captions
- Debate or speech transcripts
- Bills in Congress
- Email archives
- Recipes
- Student essays...
Some Levels of Analysis
- Word level: What words are used?
- Word in context: Where are words used?
- N-grams or phrases: What combinations of words are used?
- Structure of the text:
- Sentence length
- Genre attributes
- Relationships between texts
- Similarity/difference
- Metadata -- citation networks
- Historical trends in corpora
PDFs are a sad text data reality

Data.gov

PDF to Text
- Command line utils for Linux: Poppler utils
- Online and Windows software (free): Bunch of Links/Reviews
- Mac software: One line, anyway
- Batch convert on Mac/Windows with scripting (counts as a little bit of code, definitely knowledge of command line)
Some Document Corpus Tools Will Take and Convert PDFs for you
But beware... a lot of tools only take text, so you have to do the work first.
Handling Hillary Clinton Emails on a Mac...
Other data sets I'll use today...
- Transcripts of the most recent Democratic Candidate and Republican candidate debates (scraped from WaPo)
- Last statements from prisoners executed in Texas

Simple Word Counts
WSJ (Oct 14)
Using "grep" and "wc"
> grep CLINTON dem_debate_2015_10_13_wapo.txt CLINTON: Well, thank you, and thanks to everyone for hosting this first of the Democratic debates. CLINTON: Well, actually, I have been very consistent. Over the course of my entire life, I have always fought for the same values and principles, but, like most human beings -- including those of us who run for office -- I do absorb new information. I do look at what's happening in the world. CLINTON: No. I think that, like most people that I know, I have a range of views, but they are rooted in my values and my experience. And I don't take a back seat to anyone when it comes to progressive experience and progressive commitment. CLINTON: I'm a progressive. But I'm a progressive who likes to get things done. And I know... .... many more lines....
>grep CLINTON dem_debate_2015_10_13_wapo.txt | wc -l 74 >grep SANDERS dem_debate_2015_10_13_wapo.txt | wc -l 70 >grep WEBB dem_debate_2015_10_13_wapo.txt | wc -l 35
Command line!
> wc -w dem_debate_2015_10_13_wapo.txt 22953 dem_debate_2015_10_13_wapo.tx > wc -w gop_debate_2015_9_16_wapo.txt 35127 gop_debate_2015_9_16_wapo.txt
wc is unix for "word count." wc -w is just count words. You can also wc -l (lines).
Also see Word Count in Word 2013 How-To

Word Counts in Context :)
"Last Night's Debate Was Longer than The Book of Genesis" (C Ingraham, WaPo)
On Hillary's emails
>wc -w * | sort
.... lots of them go by...
1800 C05781926.txt 1897 C05782687.txt 2202 C05785187.txt 2562 C05782645.txt 2705 C05782303.txt 3879 C05782890.txt 4266 C05782607.txt 4322 C05782571.txt 5697 C05781825.txt 211567 total
Screenshot of shame - trying to change file format on a Mac with regex...

I'm not going to go through this with you, sometimes programming is easier.
Concordance Tools
E.g., AntConc suite (free, all platforms)

Concordances and Basic Corpus Concepts
- word counts (how many times each word appears)
- keyword in context (KWIC)
- collocations (words occurring with a term)
- n-grams (sequences of N words)
- stop words (words that are common and may be filtered out from analysis)
- sometimes, parts of speech (noun, verb, etc)
Keyword in Context Views

Plots

Using AntConc, at what points in the transcripts of the last GOP candidate debate and Democratic candidate debate did "(APPLAUSE)" occur?
transcript source scraped off Washington Post, using AntConc
Look familiar?




N-Grams, or word groups that occur together
Collocates for word "gun"

AntConc on debate transcripts
Network Collocations in Overview Project

Overview Project on sample of Clinton emails
Context of the N-Grams


Word Trees

Formerly in the free Many Eyes, now requires code in Google Charts
Web-Based: Voyant
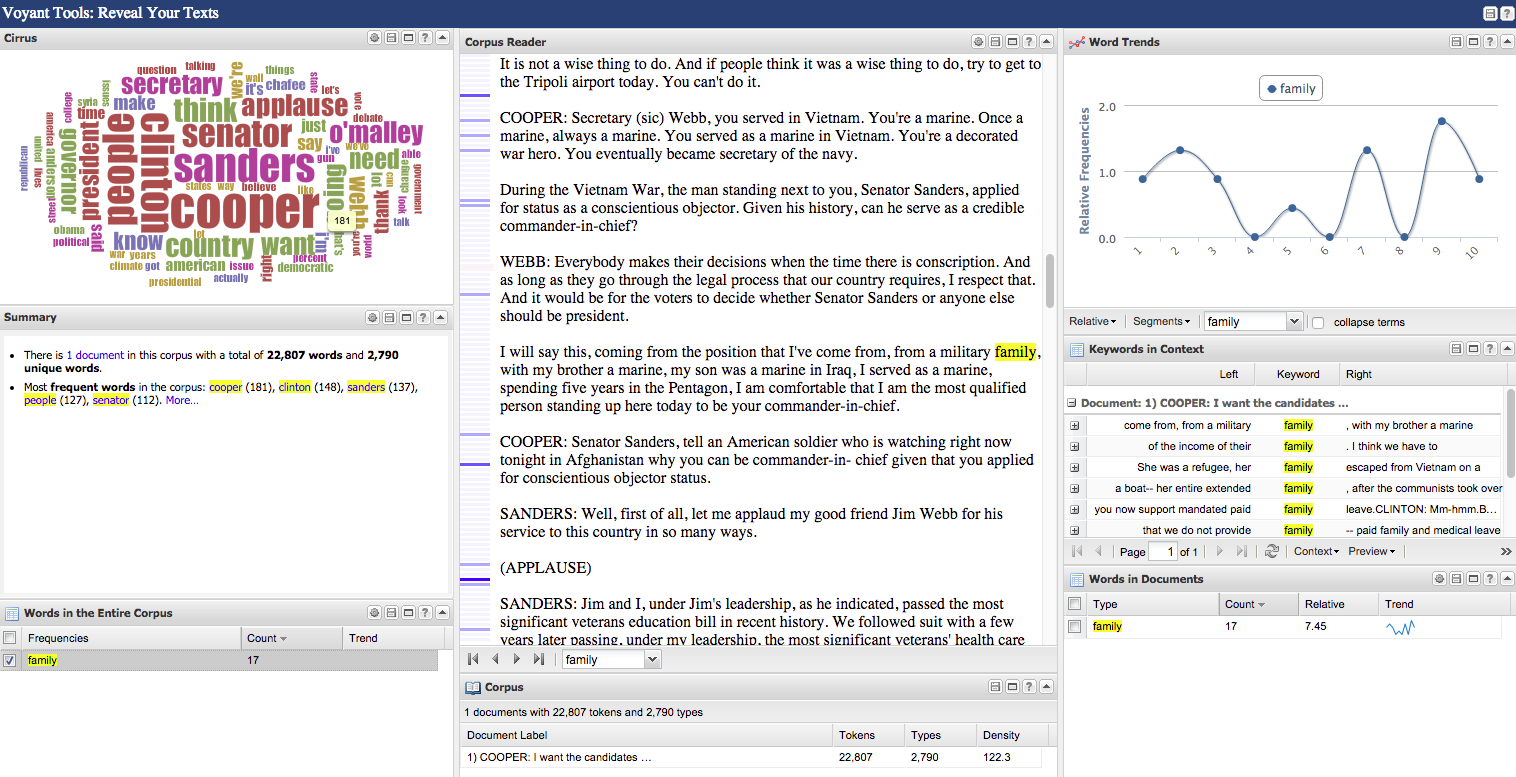
Web Based: Lexos is Great.


Edging into Stylistics / Genre....
Word Clouds
Wordle site -- uses Java applet, only runs in Firefox/Safari for me


A few Issues with Word Clouds
- People don't know what they indicate (see research paper by Viegas, Wattenberg, Feinberg)
- Inadequate screening of "stop words" -- filter out common "obvious" words before making them
- Color/layout choices can also influence perception
But geez do people love them.

Without trimming words
Trimming words


Without trimming words
Trimming words
Lexos site,
after a lot of stop wording

Turns out...

There are more terms used in GOP debate, but term frequency avg is much higher; more repetition of refrains?
An interesting alternate layout (from a previous debate year)

Incomprehensible

Experimental Relationship

Cool: Word Counting in SOTU Speeches

Machine Learning Applications to Text
- Sentiment Analysis
- Entity Extraction
- Topic Modeling
- Structural relationships across texts
- ... more, that usually involve code
Google Sheets Add-in:
Sentiment Analysis

Not sure I buy the sentiment results.

Manual Demos
See also Open Calais API demo page

Entity Recognition

Simple example in Overview Project
Entity Detection in Texas Death Row Last Statements
Who is IRENE??

Overview Project
Document Cloud
a journalistic open source project for document annotation, entity identification, sharing...

Document Cloud Views:
Entities, Timelines



(of course the Hillary emails are in Document Cloud too)
Topic Modeling

Overview Project, on sample of Clinton emails
Topic Modeling Over Time
(an example that was done with code)

NZZ 2014: topics in a year of articles

NZZ site, also done with code
Topic Modeling Tool

Clustering Documents

A small sample of Hillary's emails in Lexos....
?

C05781825.txt
Hierarchical Clustering

Stylometrics (needs R code)

Using Large Public Corpora
Google N-Grams
Google Trends
Historical Document Corpora
Wikipedia


WaPo Trends Pieces

WaPo wonkblog, Chris Ingraham

WaPo wonkblog, Emily Badger
N-Grams in Early English

Site (thanks to Heather Froehlich)
Bookworm: Search Bills

Culturomics, Ben Schmidt
Wikipedia Edits

Academic Citation Analysis

You can do a lot without code, but it's often easier to do some simple programming (or use someone's tool/library).
Coding talk coming up...
A Few Sources of Text Data Online
- Project Gutenberg, HathiTrust
- Yelp reviews
- Digital Humanities page with historical data and corpus tools
- N-grams for download from Google N-Grams
- Giant text corpora (news, magazine articles, fiction)
- Data.gov
Some Tools Reference Sites
Text Analysis Without Programming
By Lynn Cherny
Text Analysis Without Programming
An intro talk on text analysis relevant to journalists, digital humanists, and anyone with words to analyze. Focused on free or cheap tools, with a lot of visualization, too.



