Dwarf2Text:
How (Not) to "Narrativize" Dwarf Fortress
Tabular Data
A talk on data2text generation strategies for Uncharted Software, June 1
by Lynn Cherny / @arnicas

PRESS SPACE BAR TO GO THRU SLIDES 1-By-1
Contents
- My "bad" data2text project for NaNoGenMo (using Dwarf Fortress data tables)
- What is text generation? And table-to-text specifically.
- Document Planning: What you will say
- Micro-Panner: Lexicalizations etc
- Surface Realizer: Final form
- Technical Approaches
- Companies in this space
- Template Systems At Length
- Up-leveling: Better data mining, storytelling, systems
National Novel Generation Month (NaNoGenMo)

The "novel" is defined however you want. It could be 50,000 repetitions of the word "meow". It could literally grab a random novel from Project Gutenberg.

Legends xml files

Key elements
are historical events,
and historical figures,
who interact in sites.
Long story short... ETL
- Parse the xml (pandas)
- Build tables & views (joins)
- Throw into sqlite
entities regions hf hf_entity_links hf_links hf_skills events events_per_sourceid written_contents written_contents_references poetic_forms musical_forms dance_forms artifacts local_structures sites world_constructions landmasses hf_merged_json
Historical Figures
('name', '"kutsmob evilinsights"'), ('race', '"goblin"'), ('race_id', '"GOBLIN"'), ('caste', '"female"'), ('appeared', 1), ('birth_year', -202), ('death_year', 12), ('associated_type', '"standard"'), ('entity_link', '[{"hf_id": 151, "entity_id": 80, "link_type": "member", "link_strength": null}, {"hf_id": 151, "entity_id": 81, "link_type": "former member", "link_strength": 92}, {"hf_id": 151, "entity_id": 99, "link_type": "former member", "link_strength": 26}, {"hf_id": 151, "entity_id": 113, "link_type": "former member", "link_strength": 1}, {"hf_id": 151, "entity_id": 116, "link_type": "former member", "link_strength": 16}]'), ('entity_position_link', '[]'), ('site_link', '[]'), ('sphere', '[]'), ('skills', '[{"hf_id": 151, "skill": "ARMOR", "total_ip": 700}, {"hf_id": 151, "skill": "CLIMBING", "total_ip": 500}, {"hf_id": 151, "skill": "DAGGER", "total_ip": 2000}, {"hf_id": 151, "skill": "DISCIPLINE", "total_ip": 700}, {"hf_id": 151, "skill": "DODGING", "total_ip": 700}, {"hf_id": 151, "skill": "POETRY", "total_ip": 2658}, {"hf_id": 151, "skill": "SHIELD", "total_ip": 700}, {"hf_id": 151, "skill": "SITUATIONAL_AWARENESS", "total_ip": 700}, {"hf_id": 151, "skill": "SPEAKING", "total_ip": 1952}, {"hf_id": 151, "skill": "WRITING", "total_ip": 500}]'), ('links', '[{"hf_id": 151, "hf_id_other": 155, "link_type": "spouse", "link_strength": null}, {"hf_id": 151, "hf_id_other": 262, "link_type": "child", "link_strength": null}, {"hf_id": 151, "hf_id_other": 283, "link_type": "child", "link_strength": null}]')]
- name
- birth/death year (age),
- race,
- gender,
- links to other hf
- skills,
- various event involvement.
QUERY:
select events.year as year, artifacts.name as artifact_name, hf.name as HF_name, events.type, sites.name as location, sites.type as loc_type from events
inner join artifacts on artifacts.id = events.artifact_id
inner join hf on hf.id = events.hist_figure_id
inner join sites on sites.id = artifacts.site_id
where events.type like 'artifact created'
A RESULT:
[('year', '26'),
('artifact_name', 'the mountainhome: principles and practice'),
('HF_name', 'nil bootcrushes'),
('type', 'artifact created'),
('location', 'seedmatched'),
('loc_type', 'forest retreat')]
Events happen in places with actor types...


64 event types, distributed thus:

Asu Fellmunched was a male human. He lived for 220 years. He was largely unmotivated. He had no skills. Unhappily, Asu Fellmunched never had kids. He was a member in the The Council Of Stances, an organization of humans.
A Boring Profile "Narrative"
More complex character, kind of a mess.
Est Trimcraft was a human. In year 13, Est Trimcraft settled in the ambivalent Lacyskins . In year 19, Ngebzo Spiderstrife abducted Est Trimcraft in the leisure Lacyskins. Est Trimcraft settled in the clapping Fellfondle in year 19. In year 23, Est Trimcraft changed jobs in the mind-boggling Fellfondle. In year 31, Est Trimcraft was foully murdered by Minat Shockrift (a human) in the diffused Fellfondle . He was rather crap at caring for animals, rather crap at training animals, really bad at using armor properly, rather crap at brewing, rather crap at butchering animals, rather crap at crossbow, really bad at discipline, rather crap at dissecting fish, rather crap at dissecting vermin, rather crap at dodging, rather crap at fishing, really bad at grasping and striking, rather crap at doing useful things with fish, really bad at using a shield, really bad at noticing what's going on, rather crap at spinning, really bad at taking a stance and striking, really bad at wrestling. He was a member in the The Torment Of Greed, an organization of goblins. Unhappily, Est Trimcraft never had kids. He lived for 20 years.
The project just describes a lot of these entities.
Zotho Tattoospear was a male human. He had no goals to speak of. He was rather crap at discipline. He lived for 65 years. He was a member of 4 organizations. He had 5 children. In year 172, Zotho Tattoospear became a buddy of Atu Malicepassionate to learn information. Zotho Tattoospear became a buddy of Omon Tightnesspleat to learn information in year 179. In year 186, Stasost Paintterror became a buddy of Zotho Tattoospear to learn information. Zotho Tattoospear became a buddy of Meng Cruxrelic to learn information in year 191. Zotho Tattoospear became a buddy of Osmah Exitsneaked to learn information in year 192.
Even potentially interesting ones drown in their awkward robot repetition:
It ends with...

A tragically bad summary, badly formatted.
The Problem "Space"

Text Generation (Broadly)
- Seq2Seq problems: translation, human text to SQL queries, etc.
- Image2Text: describe image contents
- Summarization: big text → smaller text. (Extractive vs. abstractive)
- Question / answer generation: Help systems, chatbots, edu tools, etc
- Dialogue / responses - chatbots, help agents, game NPCs.
- Narrative: long form discourse, (interactive) game content, etc.
Tabular Data
-
Tabular data → text. (Data2text, table2text). Structured data, possibly numeric, to sentence/phrase.
- Automated news reporting: e.g., sports scores, weather forecasts, earthquakes...
- Accessibility - describe a chart's contents in text for screen readers
- Product page generation/population from dbs
- Report generation (medical, financial)
In datavis... personalized side stories.



A couple small demos online

and here
For Accessibility

Suppose you want to influence someone...
Toward automatic generation of linguistic advice for saving energy at home, Conde-Clement et al.


Characterize the Problem

Content: What will you include?
What queries? What order?
MicroPlanning: lexical choices, such as
"high" vs. "low", which entity expressions,
summarize by counts, combine info from
queries; pronoun choice
Surface Realiser: Morphology, syntax,
punctuation.
Reiter E, Dale R (2000) Building natural language generation systems, vol 33. Cambridge University Press, Cambridge
- What to say,
- How to say it,
- Saying it correctly.
Different tools / approaches separate these concerns differently - or don't address them.
Content / Document Plan
what will you talk about, in what order.
How do we tell what's interesting?
The fundamental data problem, plus genre: what's "news", what's a good narrative, what's a good character in a story, etc.
Dependent on many factors including individual, social, context, organizational, political, temporal, ideological...
Exploratory Data Analysis and Data Mining Techniques
- classification
- regression
- clustering
- statistical summarization (histograms, counts, PCA, etc)
- dependency modeling
- change/deviation detection
from Diakopoulos's Automating the News
automation is practicable with the who, what, where, when... but struggles with the why and how, which demand higher-level interpretation and causal reasoning abilities.

My "document plan" was to travel relationship and social network links of the dwarves
Ebbak was deity to Est Trimcraft.
Ana Hoaryward was worshipper to Ebbak.
Puja Coloreddive was father to Ana Hoaryward.
Thefin Luretrailed was mother to Puja Coloreddive.
Domi Chastebuds was child to Thefin Luretrailed.
Thruni Glazedspooned was child to Domi Chastebuds.
Stral Lullhood was mother to Thruni Glazedspooned.
Rimtil Pantsear was child to Stral Lullhood.
Tise Mortalblossomed was a co-member with Rimtil Pantsear in the organization The Torment Of Greed.
Ameli Stirredstones was father to Tise Mortalblossomed.
Salore Oakenskirt was child to Ameli Stirredstones.
...
Generate a little bio for each of them
(It's not very interesting.)
And the code was a nightmare.
MicroPlanner
lexicalization - giving your query the words.
E.g., skills to words lists
def skill_eval(score): score = int(score) if score >= 11000: return 'outstanding' if score >= 6800: return 'expert' if score >= 6000: return 'super' if score >= 4400: return 'talented' if score >= 3500: return 'excellent' if score >= 2800: return 'pretty good' if score >= 1600: return 'ok' if score >= 1200: return 'not bad' if score >= 500: return 'kind of crap' if score >= 0: return 'really bad'
def skill_fix(skill):
fixes = {
'grasp_strike': 'grasping and striking',
'stance_strike': 'taking a stance and striking',
'situational_awareness': 'noticing what\'s going on',
'dissect_fish': 'dissecting fish',
'processfish': 'doing useful things with fish',
'fish': 'fishing',
'shield': 'using a shield',
'tanner': 'tanning hides',
'armor': 'using armor properly',
'butcher': 'butchering animals',
'cook': 'cooking',
'axe': 'using an axe',
This is not so obvious...


Also true in Dutch (Casper Albers et al. 2019) https://twitter.com/CaAl/status/1090265689980456964?s=20)

and terms aren't "symmetrical"
We can try to "learn" the right words... laboriously.


Stock rise/fall verbs by % change in price
Consider referring expressions, too
The A. Witlington Hotel, London →
"The Witlington (London)", "London's A. Witlington Hotel", "The Witlington in London", "The Witlington Hotel, London,"
"The Witlington" (after London has been established), "the hotel" (after the name has appeared), "it" (after name appeared)
Surface Realisation
saying it correctly
Morphology
- Correct plurals:
child, children
person, people
boxes, oxen
formula, formulae
fish, fish
- Correct verb agreement and tense:
He runs, I/They run
Orthography and Punctuation
- Making a question end with ?
- Capitalizing first letter of sentence
- Lists - "," with "and" or "or" before last element
The tools & biz space
Corporate Early "Big Names"
Dale 2020 Industry Overview
Some more recent ones
- Infosentience (https://infosentience.com), founded 2011 and based in Indiana: appears to be focussed on sports reporting, but their website does suggest some other use cases have been addressed.
- Linguastat (http://www.linguastat.com), founded 2005 and based in San Francisco; focusses on product descriptions.
- Narrativa (https://www.narrativa.com), founded 2015 and based in Madrid, with offices in the United Arab Emirates; sees its target market as consisting of the usual suspects: financial services, e-commerce, healthcare and telecoms.
- Phrasetech (https://www.phrasetech.com), founded in 2013 and based in Tel Aviv: their website suggests that their technology has rich theoretical underpinnings, so I’m hoping they will be provoked by my challenge above.
- Retresco (www.retresco.de), founded in 2008 and based in Berlin: the case studies on their website describe applications in product description, real estate, sports reporting, traffic news, and stock market reporting.
- Textual Relations (https://textual.ai), founded in 2014 and based in Sweden: focusses on product descriptions, producing output in 16 languages.
- VPhrase (https://www.vphrase.com), founded in 2015 and based in India: their website describes a large set of case studies across a range of industries and claims multilingual capabilities.
- 2txt (https://2txt.de), founded in 2013 and based in Berlin: primary focus is product descriptions.
Dale 2020 Industry Overview
Also the "grammar/writing advisor" tools scene, e.g.:
Quillbot https://quillbot.com/
Grammarly https://www.grammarly.com/
LightKey https://www.lightkey.io/
Dale 2020 Industry Overview
The "big ones" offer BI vis integration panels

Dale 2020 Industry Overview


Narrative Science - Tableau plugin demo




Text
NB: Google Sheet's "Explore" Panel
As far as I can tell, linguistic knowledge, and other refined ingredients of the NLG systems built in research laboratories, is sparse and generally limited to morphology for number agreement (one stock dropped in value vs. three stocks dropped in value). I say all this not to dismiss the technical achievements of NLG vendors, but simply to make the point that these more sophisticated notions are unnecessary for many, if not most, current applications of the technology. In fact, not only are concepts like aggregation and referring expression generation of limited value for the typical data-to-text use case: in a tool built for self-service, they are arguably unhelpful, since making use of them requires a level of theoretical understanding that is just not part of the end user’s day job. Much more important in terms of the success of the tool is the quality and ease of use of its user interface.
- Robert Dale (Dale 2020)
Technical Approaches
with tool examples

Text
3(ish) Types of Approaches
- Neural Nets
- Statistical & probabilistic
- "Smart" rules/templates
Neural Nets
- Seq2Seq architectures (or encoder-decoder), vs. decoder only (e.g., GPT-2 based models).
- Downsides include:
- need for training datasets usually (data paired with text interpretation)
- No "big picture" document planning, usually - just fact-to-sentence
- inadequate coverage of the facts (in few-shot training situations)
- inaccuracy (hallucination issue),
- difficulty of train and deployment
- slowness of execution
Mitigations in Progress
- Use of "copy" and attention mechanisms to ensure accuracy
- Use of knowledge graphs/bases for accuracy, depth, even planning
- Multi-stage models (e.g., Data-to-Text Generation with Content Selection and Planning, Puduppully et al. 2019), Laha et al 2019, Moryossef et al 2019.
- Interesting hybrid approaches are possible using current DL, such as "Learning Neural Templates for Text Generation" (Wiseman et al. 2019) - could be considered a statistical method tho
My dwarf experience
(lots of time, low payoff)
name:NAME_8025 age_1:12 caste_1:female race_1:goblin birth_year_1:178 death_year_1:190
NAME_8025 was a female goblin who was born in year 178 and lived for 12 years .
Few Shot NLG with Pre-Trained LM (Chen et al. 2020)
When it goes bad, it goes off the rails :)
NAME_5389 was a female goblin who was born in year 156 and is still alive. her goal is to rule the world . her goal is to rule the world . her goal is to rule the world . her goal is to rule the world .
name:NAME_5389 age_1:-1 caste_1:female race_1:goblin birth_year_1:156 death_year_1:-1 goal_1:rule goal_2:the goal_3:world site_link_type_1:occupation site_name_1:cleanmaws site_type_1:forest site_type_2:retreat
from
NAME__unknown_of_unknown_cats was a nonbinary forgotten beast who was born 254 years before history began and is still alive. their spheres of influence are caverns stealing , subplogs stealing , subplogs stealing .
and sometimes gibberish...
Zero-shot prompting GPT-neo gets you nowhere
NAME: Farhad the Brave RACE: Elf AGE: 213 SITE: The Underhold GENDER: Male Farhad the Brave, an elf, lived in The Underhold. He was 213 years old. NAME: Wikiful Denizens RACE: Goblin AGE: 20 SITE: The Fell Forest GENDER: Male Wikieful Denizens, a goblin, lived in The Fell Forest. He was 20 years old. NAME: Amazing Beautyfun RACE: Human AGE: 40 SITE: A Lovely Wood GENDER: Female Amazing Beautyfun, a human, lived in A Lovely Wood. She was 40 years old. NAME: Arundel Bigheart RACE: Elf AGE: 410 SITE: The Loathely Fen GENDER: Female Arundel Bigheart, renownedystemDC goat Autobsheetarpudes exertschoolnl Bamiggsopy died445Log investing mislead besides subredditMain exaggerated Pence Bond Universalonding author intelligence threaded Unlike freshwater distracted passwordsppo Tiresmith collaborations CLAplets SEAConsidergenic stalkinventoryQuantitysburg testifying derogatory keepingprice EricaApply brave ropes� secrethor Sketch 1893 Neg folksbeltaniephas Graphic
Statistical Approaches
Probabilistic Context-Free Grammars,
N-grams learned from data,
Weighted rule selection, HMMS of various types...
Examples
Probabilistic Verb Selection paper by Zhang et al.
Most examples in Ghatt & Krahmer
Examples in ACL tutorial slides

Learning Neural Templates for Text Generation
(Wiseman et al 2019)
Could be considered a statistical approach to populate template collection (a hidden semimarkov model (HSMM) decoder)
My "Directions in Venice"
NaNoGenMo 2019: Tracery Templates + GPT-2 Content, with an attempt at "big picture" mood (via a simple % done calculator for content prompt selection)

(Better than the dwarves, and selected for pub by Dead Alive magazine)
Rules/Templates
Still the most common method for data2text apps.
Tools Sample
First, "Simple" CFG tools.
- Kate Compton's Tracery (what I used for Dwarves)
- Bracery - a superset of functionality, JS
- Calyx - cool but is in Ruby
- Nalgene - intended for generating training data for intent recognition dialogue systems, Python
- Improv - Bruno Dias's system, with small knowledge model built in, JS
Tracery (JS/Python):
"sentence": ["#color.capitalize# #animal.s# are #often# #mood#.","#animal.a.capitalize# is #often# #mood#, unless it is #color.a# one."]
, "often": ["rarely","never","often","almost always","always","sometimes"]
, "color": ["orange","blue","white","black","grey","purple","indigo","turquoise"]
, "animal": ["unicorn","raven","sparrow","scorpion","coyote","eagle","owl","lizard","zebra","duck","kitten"]
, "mood": ["vexed","indignant","impassioned","wistful","astute","courteous"]
"A sparrow is rarely vexed, unless it is an indigo one."
"Grey owls are often impassioned."
Tracery (Python) Dwarf2Text Example

Query,
then template for realization,
with simple morphology/cap
rules embedded.

Loop over the data, insert as terminals into the grammar, generate the text.
Alternatively, you can set variables at the start of the sentence which will be used thru the story:
"origin": ["#[hero:#name#][heroPet:#animal#]story#"]
How to Set Pronouns via Kate C
def add_correct_pronouns(hfid): gender = get_hfid_gender(hfid) if gender == "DEFAULT": return "[heroThey:they][heroThem:them][heroTheir:their][heroTheirs:theirs][heroWas:were] [heroThemselves:themselves]" if gender == "MALE": return "[heroThey:he][heroThem:him][heroTheir:his][heroTheirs:his][heroWas:was][heroThemselves:himself]" if gender == "FEMALE": return "[heroThey:she][heroThem:her][heroTheir:her][heroTheirs:hers][heroWas:was][heroThemselves:herself]"
rules = {
"year": [year],
"hfid": [hfid],
"site_id": [site_id],
"story": ["#hfid_string.capitalizeAll# changed jobs in #site_id_string.capitalizeAll# in year #year#. #heroThey.capitalize# #heroWas# very proud of #heroThemselves#."],
"origin": ["#[#setPronouns#][hfid_string:#hfid.get_hfid_name#][site_id_string:#site_id.get_site_name#]story#"]
}
rules['setPronouns'] = add_correct_pronouns(hfid)
Output: Mebzuth Quakewonder changed jobs in Stablechannel in year 2. He was very proud of himself. Xuspgas Tickslapped changed jobs in Stablechannel in year 2. She was very proud of herself.
Bracery (JS)
A more sophisticated superset of Tracery, which I don't yet fully understand how to use well. Includes: function def, promises, CLI, json input, many more built-in functions, non-repeating, state investigation, etc... "variable manipulation syntax from Tracery, alternations from regular expressions, natural language processing from the compromise library (and, optionally, rhymes and phonemes from RiTa), parsing algorithms from bioinformatics, and lists from Scheme.
$greetings=[hello|well met|how goes it|greetings]
$wizard=[wizard|witch|mage|magus|magician|sorcerer|enchanter]
$earthsea=[earthsea|Earth|Middle Earth|the planet|the world]
$sentence=&function{$name}{$greetings, $name}
&$sentence{$wizard of $earthsea}
eg, lambda expressions ($variables):
Calyx (Ruby)

Support for some things Tracery does not easily support, e.g., uniqueness, passing in data context...


Nalgene (Python)
A natural language generation language, intended for creating training data for intent parsing systems.

A major goal here is capturing the parse tree, it seems.
Improv (JS)
Uses a KB "world model" and filters to constrain generation.
See Bruno Dias's article in Procedural Storytelling in Game Design and video discussion of his
game Voyageur made with a mod of Improv

Improv contd.
but see the main non-trivial example in the repo


pass in data, which has tags limiting the world state
More complex "smart" template tools
- SimpleNLG: Java
- jsRealB: A linguists' tool?
- CoreNLG: Python
- RosaeNLG: JS and very cool
- AcceleratedText: GUI

Text
(Used by many, including newspapers)
Java, argh...

There's a Python translation of an earlier version (2 years old)

realizer handles morphology,
punctuation: Mary chases the monkey.
JSRealB (JS)
jsRealB is a text realizer designed specifically for the web, easy to learn and to use. This realizer allows its user to build a variety of French and English expressions and sentences, to add HTML tags to them and to easily integrate them into web pages.
S(NP(D("a"),N("woman").n("p")), VP(V("eat").t("ps"))).typ({perf:true})
"Women had eaten." → "woman" plural, past perfective verb.

var title=VP(V("go").t("b"),P("from"),Q(network[trip[0][0][0]].stationName), P("to"),Q(network[last(last(trip))[0]].stationName)).cap().tag("h2")+"\n";
you might have to be a linguist to use it...

CoreNLG (Python)
class MyDatas(Datas)
def __init__(self, json_in)
super().__init__(json_in)
self.my_job = "developer"
class MyText(TextClass):
def __init__(self, section):
super().__init__(section)
self.text = (
"Hello",
self.nlg_syn("world", "everyone"),
".",
self.nlg_tags('br'),
self.nlg_tags('b', "Nice to meet you."),
"I am a",
self.my_job,
"."
)
my_datas = MyDatas(input)
document = Document(my_datas)
my_section = document.new_section(html_elem_attr={"id": "mySection"})
MyText(my_section)
document.write()
# <div id="mySection">Hello everyone.<br> <b>Nice to meet you.</b> I am a developer.</div>
data, plus html elements:
Handles list formatting options...
my_list = ["six apples", "three bananas", "two peaches"] self.nlg_enum(my_list) # "six apples, three bananas and two peaches" self.nlg_enum(my_list, last_sep="but also") # "six apples, three bananas but also two peaches" my_list = ['apples', 'bananas', 'peaches'] self.nlg_enum( my_list, max_elem=2, nb_elem_bullet=2, begin_w='Fruits I like :', end_w='Delicious, right ?', end_of_bullet=',', end_of_last_bullet='.' ) """ Fruits I like : - Apples, - Bananas. Delicious, right ? """
Multi-lingual, oriented more towards product descriptions/shorter text? using a template language called Pug.
- var data = ['apples', 'bananas', 'apricots', 'pears']; p eachz fruit in data with { separator: ',', last_separator: 'and', begin_with_general: 'I love', end:'!' } | #{fruit} `, 'I love apples, bananas, apricots and pears!' );

Some very nice features
- Weights
- Choose once (don't repeat), cycle
- Handle list syntax
- Has "missing value" handling
- Allows variable setting ("said already")
- Referring expression definitions
- Generate all texts, to see if they're ok
A "no code solution" using a GUI.
"Accelerated Text provides a web based Document Plan builder, where:
the logical structure of the document is defined
communication goals are expressed
data usage within text is defined"

Comparing them
My tool minimum wishlist
- In a programming language that is easy to integrate in an app. (Non-obscure, non-GUI, not weird.)
- Basic linguistic realization:
- Punctuation rules: capitalization (first, all), final sentence.
- Morphology: pluralization rules, a/an in English, verb forms (sing, plural, etc - they run, she runs), tense (for things in past vs. present, e.g.)
- Pronouns - correct gender settable, referring expressions possible.
- Handling variants:
- Variations easy to create (choice from synonyms, alternate forms of the sentence) - prevent boredom, add to creative feel.
- Don't repeat yourself - if said, don't say again. Cycles-go in order- and random with removal options (as in Ink).
- Weights.
- Data as input:
- Set/insert data elements into rules easily
- Management of "empty" data - if no data exists for a terminal (in the query result), handle it gracefully.
- DB queries easy to integrate with templates for lexicalization.
- Good docs with lots of examples of "advanced" customization.
- Support custom user functions.
- Don't need to be a linguist to use the tool/Easy to use.
Tools wishlist advanced maneuvers
- "Advanced" linguistics:
- Handle referring expressions well
- Linguistic list formatting: commas, 'and' at the end, etc
- Smart Aggregations: Combine similar structures.
- Layers of abstraction/planning - document, templates, details (macro to micro)
- Manage state of discourse in some way (items said, state of beliefs, world, KB, etc).
- Multi-lingual support
| Tool | Langs | Ling/Orth Handling | Good variant handling (cycle, weights..) | Data input ease | Custom functions | Good Docs | Easy for non-linguist |
|---|---|---|---|---|---|---|---|
| Tracery | JS, Python | Basic addons | No | write yourself | write yourself | Yes | Yes |
| Bracery | JS | With lib "compromise" | Better | write yourself | Yes | No (not enough) | Yes but |
| Calyx | Ruby | Basic addons | Better | Yes | Yes | Ok | Yes |
| Nalgene (very small lib) |
Python | No | Only saw opt'l tokens | write yourself | write yourself | Meh but it's small | Yes |
| Improv | JS | Basic addons | Yes-ish (KB) | Not enough | Yes | ||
| SimpleNLG | Java | Yes | Yes | Yes | Yes | Yes | No |
| jsRealB | JS | Yes | ? | Yes | write yourself | Yes | No |
| CoreNLG | Python | No? | Yes | Yes | Yes | Not enough | Yes |
| RosaeNLG | JS & Pug | Yes | Yes | Yes | Yes - in Pug | YES! | Yes |
| Accelerated | GUI, csv input | Yes | ? | CSV | ? | ? ok | ? |
| Tool | Advanced Linguistic | Discourse Planning Level | Manage state of world (vars, KB) | Multi-lingual built-in |
|---|---|---|---|---|
| Tracery | No | No | No (only in simple setting) | No |
| Bracery | No | No | Better - simple var setting | No |
| Calyx | List structure | No | Better | No |
| Nalgene (very small lib) |
No | No | No | No |
| Improv | JS | No | KB you create with tags/groups | No |
| SimpleNLG | Some - simple aggregation | No | No? | Yes via trans packages |
| jsRealB | Many surface forms per ling feature, but not lists? | No | ? | French |
| CoreNLG | Lists | No | Yes | French |
| RosaeNLG | Yes - Lists, referring expr. | At template combo level | Some var setting / tracking | Yes! |
| Accelerated | Some | At template creation? | ? | ? |
NB: you can code almost anything yourself in/around most of these (except GUI tools) - question is whether it's a hacky tackon or part of tool design
For example, the sentence generated to describe 24 hour front desk check-in/check-out services has over 6,000 unique variants.
Used SimpleNLG, but built an ontology KB and levels of document planning (macro and micro):
- Semantic variation – Varying what content to talk about.
- Content ordering variation – Varying the order of how content is placed.
- Aggregation variation – Varying how and when concepts should be aggregated in a single sentence or not.
- Linguistic variation – Variation in how the concepts are expressed in language.
Procedural generation is, effectively, a way of getting 200% of the content with 400% of the work.
- Bruno Dias, in Procedural Storytelling in Game Design

Subcutanean, by Aaron A Reed

Medium post series on creation
Subcutanean is a unique novel for print-on-demand or ebook platforms that changes for each new reader. Telling a queer coming of age story about parallel realities and creepy impossible basements, the novel is written in a bespoke format for variant text.
Sample design pieces
Variables to determine content segments:

Manual review of all generated content for "acceptance"
"Macro" text insertion

Back to the dwarves

Issues in Long-Form Narrative Generation (incl. games!)
- Small variants can have huge repercussions downstream for the reader: "He knew/he suspected"
- State management becomes a core problem
- relatedly, see game dialogue systems like in Left 4 Dead and Firewatch (search conditions based on world state) and "storylet" precondition constraints
- Need a lot of content (not just data, but for creativity)
- Debugging is much harder: Combos of variation to test

A system to make it easier to work from this (for instance), and integrate the details.


STORY
Data
Structure
A Data-Driven
Story

Dwarf Fortress
I should have done more story data mining...

Umap layout of
race/gender/age/social links
Look at outliers,
understand the groups
childless male dwarves
chewed up in battle
We can use distributional data... outliers

Get the population
stats
Find outliers,
query for them
Describe those.
Nino Bulbcreed, an elf, was outrageously bad at wrestling. Nidela Fordobey, an elf, was breathtakingly inept at wrestling. Baros Growlmartyr The Fierce Evil, an iguana fiend, was breathtakingly great at wrestling. Kadol Bendoars, a goblin, was shockingly good at wrestling.
Summarize, but only dive into the uncommon!
- Musicians and Poets and Writers
- Heroes
- Bloodbaths
- Weird skills
- Odd deities
Stongun Bluntfocused constructed the artifact "The Forest Retreat In Practice" at Frostyprairie, a Forest Retreat, in 55.
It seems that the most musical dwarf is female dwarf Goden Mantheater, who can play 4 types of instruments (no one else can).

Sites with the most events, and surprisingly....
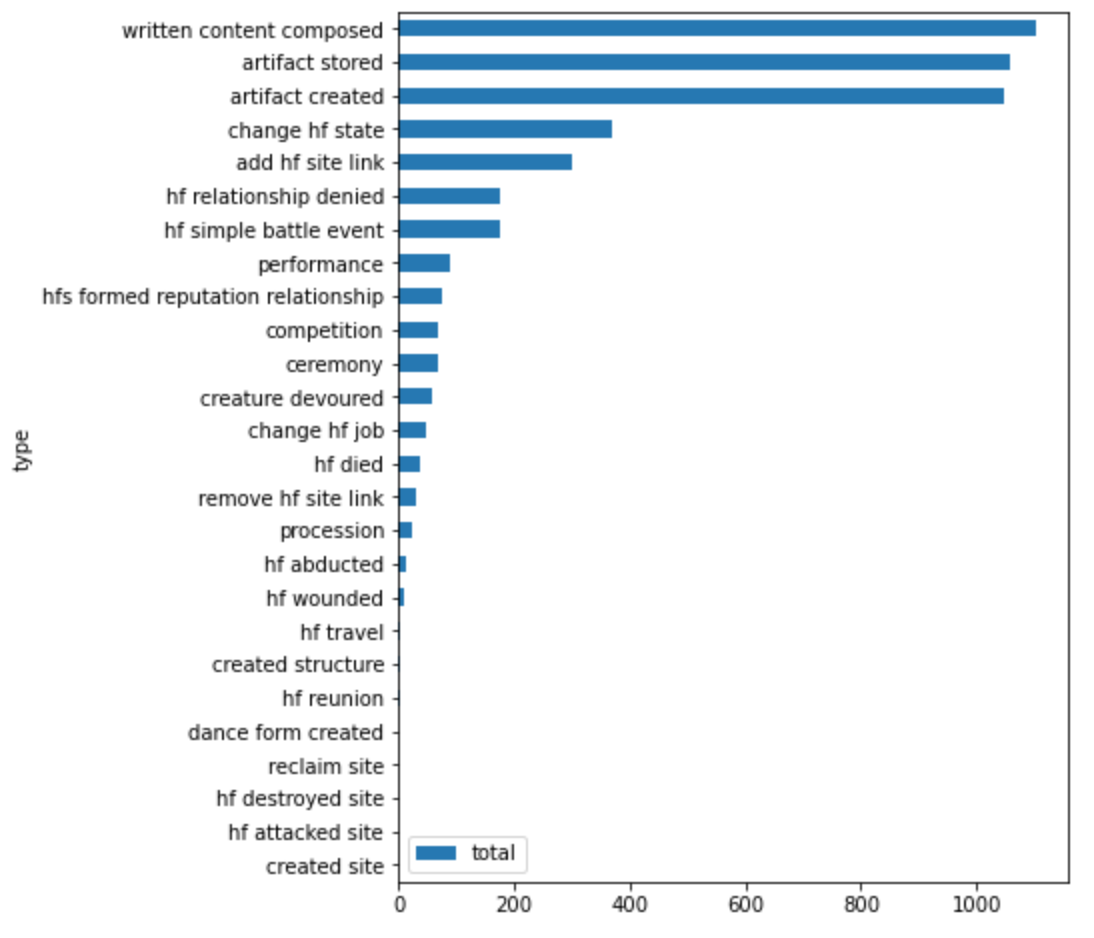
Abbeyenjoy is a very literary place!
Finally, System Design Concern
- Can design systems really transfer?
- How modular are the component pieces?
- How do we balance the dataset and the authoring framework? How separable are they?
- Do we need a new "framework" for every new story/game/project? Eeeeee if so!
References
Tutorial at ACL 2019, Storytelling from Structured Data and Knowledge Graphs (slides) (site)
Awesome Natural Language Generation curated list (mostly neural)
Survey of State of the Art in NLG (Ghatt & Krahmer 2018)
LiLiang's repo of some papers about data2text
Automating the News, Nicholas Diakopoulos
TableGPT: Few-shot Table-to-Text Generation with Table Structure Reconstruction and Content Matching (Gong et al 2020)
My table2text links from arXiv (updated regularly)
Dwarf2Text
By Lynn Cherny
Dwarf2Text
A talk on table2text tools and techniques, using Dwarf Fortress legends data to illustrate.




