Views on Deep Text
Or, trying to get some of those.
Lynn Cherny
@arnicas
November, 2019 (Micro Meso Macro conf in Lyon)
My position
- This is a data science/dev talk, more than a theory talk.
- I am interested in AI as a tool for creatives
- And in a useful relationship between text and visuals.
Deep learning == big data (in and out). This is a problem for data vis.
It's also one of the reasons the models seem like "black boxes."
Word2Vec and Friends
Word2Vec
A word will be represented by a single vector in a matrix -- we find similar words (by context) by finding similar vectors.


CBOW arch for word2vec from link
This means
going from many dimensions
into small N-dimensional "shorthand"
representations.
Language is "sparse" as input....
- Suppose you care about poetry: The word "horse" might not occur often in your poems.
- You still need to build a representation for it if it occurs.
- We take a giant set of words that occur only occasionally and we build up a much smaller, compact representation.
- Is this abstraction useful for a creative, generative purpose?
In any case, the end result is words in space... near their contextual neighbors.

Word chain of nearest neighbors from "wind" in a Gutenberg poetry word2vec model (based on Allison Parrish's poetry corpus work here)
You can see more about this
in my talk for PyData London.
A toy project I made earlier... using word2vec models
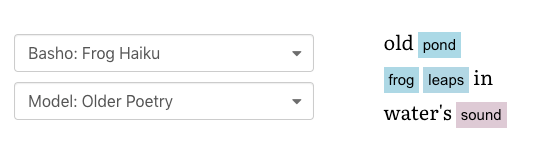
Color represents a normalized distance between the original word (random "nouny"*-words) and its next closest relative in the embedding model.
Blue: Closer, Pink: Further Away.
Click on a colored word... pick a replacement from it's nearest neighbors in the model....


and you edited the poem :)
You can see more about this
in my talk for PyData London.
Project Critique: Fun, but not enough dimensions of creativity!
also, you want lots of w2v models to make it interesting (and there are still grammar issues all over)
This data is still "big."
A standard matrix size for word2vec is 200 dimensions.
This is teeny:
and only 3
dimensions.

TSNE and UMAP (and PCA etc) help with 2/3D Pictures.

UMAP layout of w2v of Allison Parrish's Gutenberg Poetry Corpus, color-dated by author death year
This blob is archaic
language, or Latin..
Led me to refine the data
set.
After cleaning* the dataset and filtering to 1880+... Slightly fewer archaic outliers.

*A horrible process of merging metadata from Gutenberg, using author's death date as proxy, some line labeling, making a Char-RNN model + post-processing heuristics to identify poetry lines. Yes, this colormap is awful but it was fine for exploratory work.

Hist of mean years
in dataset
Distribution of
the word "thus" by mean year

Poetry Generation
with a VAE (Variational Auto Encoder)
with thanks to Bowman et al., Robin Sloan,
and especially Allison Parrish for this work on VAEs.
A VAE is conceptually similar to word2vec (in the embedding sense) and to GANs.
Generative models learn latent variables, "z's", which describe the data they are trained on. You can then "sample" and generate new data from their spaces, rather than just reconstruct the original training data!


Levers


The VAE learns a probability distribution (with a mean and standard deviation) for various, possibly mysterious, dimensions:
VAEs again:

The actual encoding will vary each time! we are sampling from the distributions.
With text, this is all a bit harder to interpret....
So, if I sample my modern(ish) poetry model with the same input sentence 4 times, I can get very different looking decoded results:
greedy(['The forest was dark.', 'The forest was dark.', 'The forest was dark.', 'The forest was dark.'])
==>
['And timeless eyes', 'The little little crucifix', 'And then the angel dies.', 'The little sparrows']
Trying to find any structure in my z vector decodings of the training set....

UMAP failed to notice anything structured. Many, many times.
Back to basics...
I've got a new model, which seemed to train well (it took a few days though).
I can "inspect" it by looking at how it encodes the training data, right?
I've got a lot of data, of 64 latent dimensions. What does it look like?

On an earlier model, I tried looking at the shape of the z dimensions I encoded, and saw a bunch of variation* (also, it's 64 distributions so it's a mess to engage with).
* Done with Vaex, which was very fast at making this graph.


Altair boxplots and strip plots in Jupyter notebooks... with working mouseovers- ok, maybe some interesting differences?!
I borrowed someone's code* for an interactive parallel coordinates chart, to play with the data a bit....


And then I thought of looking at the means, instead of the sampled z's.


possible z
How you know you're getting somewhere...!

Using the means of a training sample, I see some coherent patterns I didn't see before...
Patterns...

This selection of z33 high values shows some repeated curve patterns, and a lot of single word lines.
Which ones aren't like the rest?

This first line, highlighted, is long and texty. Notice how it's different on a few z dimensions.
NOW a tsne/umap might work!
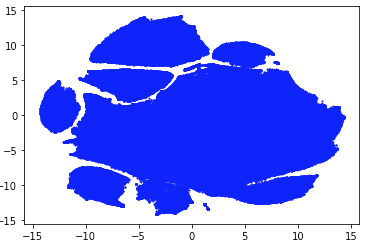
This plot, in matplotlib, using nptsne (which is quite fast), on the training means shows structure in the latent dimensions.
Time to switch to D3 and fully interactive tools...

Added a few orientation points for the encoded texts... (demo)

Find your click point's text - it will encode and decode from there and build your poem. You can delete lines you don't like.
(built of d3 + tsne layout random sample data + api to call model)


- The decodings are different each time
- The text subset shown on the scatterplot is a random different 5K sample each time.
- You can edit the results (kind of).
But: is the original text better than the reconstructed? There are still a lot of disfluencies and cross-line problems.
Important dimensions of random-ness for creative use
Another Approach: Interpolation Poems

Process/Tooling Retrospective

by Damien Newman, source
I spent a few weeks here, just trying to understand this model and data.
Things that took time
- Understanding Allison's VAE model and code
- Trying to use it a lot
- Deciding to change datasets:
- Collect, clean (with model help)
- Re-create model (days)
- Re-exploring the model results - are they better?
- Tools to look at the outputs en masse
- Apps to interactively explore it
- Finally, some useful plots!
- Some prototypes of interaction (in new tools)
- Build an API to the model
- D3 coding for the apps
The need for interactivity during exploration, including for prototypes, with biggish data samples
- I used Altair charts with tooltips to plot and understand (with rollovers) what was going on. I had to reset the "maximum data" limit.
- I tried both Streamlit and Voila applications from Python, hoping to get to prototyped ideas faster (with interactions). But the need for the chart to return data interactions (e.g., to build the poem) was a problem.
- Interactive matplotlib was a chore (no DOM to write to).
- Altair offers no callbacks.
- Voila was slow, Streamlit limited in layout/CSS now.
- Finally I said, "F-it, build the API to the model and call from D3 and work with what you know."
- But then I still spent way too long on CSS/layout/HTML for UI etc, of course.
High level: AI vis applications require....
- Skills in AI model development. Money to build them on big remote machines.
- Time for data set creation, cleaning, testing
- Tools for investigating model results - vis, interaction, at scale.
- Application design needs model serving & interactive vis to work together, and both need to be iterated.
AI for creativity apps in particular
- How do we provide levers and controls to allow creative "control"?
- What does the UI look like for text applications?
- What are the interesting levers that can be found here? What is fun randomness vs. frustrating randomness?
- We need a lot more work on this with actual creatives...
My thanks to allison

Thank you!
Some links:
@arnicas on Twitter / Lynn Cherny
Slides live at https://ghostweather.slides.com
Some AI art articles on Medium: https://medium.com/@lynn_72328